 電子發燒友App
電子發燒友App


摘 要:分類是數據挖掘、機器學習和模式識別中一個重要的研究領域。通過對當前數據挖掘中具有代表性的優秀分類算法進行分析和比較,總結出了各種算法的特性,為使用者選擇算法或研究者改進算法提供了依據。
1 概述
分類是一種重要的數據挖掘技術。分類的目的是根據數據集的特點構造一個分類函數或分類模型(也常常稱作分類器),該模型能把未知類別的樣本映射到給定類別中的某一個。分類和回歸都可以用于預測。和回歸方法不同的是,分類的輸出是離散的類別值,而回歸的輸出是連續或有序值。本文只討論分類。
構造模型的過程一般分為訓練和測試兩個階段。在構造模型之前,要求將數據集隨機地分為訓練數據集和測試數據集。在訓練階段,使用訓練數據集,通過分析由屬性描述的數據庫元組來構造模型,假定每個元組屬于一個預定義的類,由一個稱作類標號屬性的屬性來確定。訓練數據集中的單個元組也稱作訓練樣本,一個具體樣本的形式可為:(u1,u2,……un;c);其中ui表示屬性值,c表示類別。由于提供了每個訓練樣本的類標號,該階段也稱為有指導的學習,通常,模型用分類規則、判定樹或數學公式的形式提供。在測試階段,使用測試數據集來評估模型的分類準確率,如果認為模型的準確率可以接受,就可以用該模型對其它數據元組進行分類。一般來說,測試階段的代價遠遠低于訓練階段。
為了提高分類的準確性、有效性和可伸縮性,在進行分類之前,通常要對數據進行預處理,包括:
(1) 數據清理。其目的是消除或減少數據噪聲,處理空缺值。
(2) 相關性分析。由于數據集中的許多屬性可能與分類任務不相關,若包含這些屬性將減慢和可能誤導學習過程。相關性分析的目的就是刪除這些不相關或冗余的屬性。
(3) 數據變換。數據可以概化到較高層概念。比如,連續值屬性“收入”的數值可以概化為離散值:低,中,高。又比如,標稱值屬性“市”可概化到高層概念“省”。此外,數據也可以規范化,規范化將給定屬性的值按比例縮放,落入較小的區間,比如[0,1]等。
2 分類算法的種類及特性
分類模型的構造方法有決策樹、統計方法、機器學習方法、神經網絡方法等。按大的方向分類主要有:決策樹,關聯規則,貝葉斯,神經網絡,規則學習,k-臨近法,遺傳算法,粗糙集以及模糊邏輯技術。
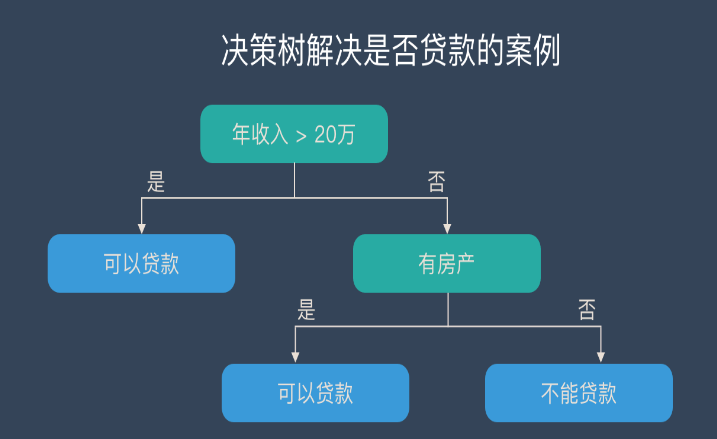
2.1 決策樹(decision tree)分類算法
決策樹是以實例為基礎的歸納學習算法。它從一組無次序、無規則的元組中推理出決策樹表示形式的分類規則。它采用自頂向下的遞歸方式,在決策樹的內部結點進行屬性值的比較,并根據不同的屬性值從該結點向下分支,葉結點是要學習劃分的類。從根到葉結點的一條路徑就對應著一條合取規則,整個決策樹就對應著一組析取表達式規則。1986年Quinlan提出了著名的ID3算法。在ID3算法的基礎上,1993年Quinlan又提出了C4.5算法。為了適應處理大規模數據集的需要,后來又提出了若干改進的算法,其中SLIQ (super-vised learning in quest)和SPRINT (scalable parallelizableinduction of decision trees)是比較有代表性的兩個算法。
(1) ID3算法
ID3算法的核心是:在決策樹各級結點上選擇屬性時,用信息增益(information gain)作為屬性的選擇標準,以使得在每一個非葉結點進行測試時,能獲得關于被測試記錄最大的類別信息。其具體方法是:檢測所有的屬性,選擇信息增益最大的屬性產生決策樹結點,由該屬性的不同取值建立分支,再對各分支的子集遞歸調用該方法建立決策樹結點的分支,直到所有子集僅包含同一類別的數據為止。最后得到一棵決策樹,它可以用來對新的樣本進行分類。
某屬性的信息增益按下列方法計算。通過計算每個屬性的信息增益,并比較它們的大小,就不難獲得具有最大信息增益的屬性。
設S是s個數據樣本的集合。假定類標號屬性具有m個不同值,定義m個不同類Ci(i=1,…,m)。設si是類Ci中的樣本數。對一個給定的樣本分類所需的期望信息由下式給出:
其中pi=si/s是任意樣本屬于Ci的概率。注意,對數函數以2為底,其原因是信息用二進制編碼。
設屬性A具有v個不同值{a1,a2,……,av}。可以用屬性A將S劃分為v個子集{S1,S2,……,Sv},其中Sj中的樣本在屬性A上具有相同的值aj(j=1,2,……,v)。設sij是子集Sj中類Ci的樣本數。由A劃分成子集的熵或信息期望由下式給出:
熵值越小,子集劃分的純度越高。對于給定的子集Sj,其信息期望為
其中pij=sij/sj 是Sj中樣本屬于Ci的概率。在屬性A上分枝將獲得的信息增益是
Gain(A)= I(s1, s2, …,sm)-E(A)
ID3算法的優點是:算法的理論清晰,方法簡單,學習能力較強。其缺點是:只對比較小的數據集有效,且對噪聲比較敏感,當訓練數據集加大時,決策樹可能會隨之改變。
(2) C4.5算法
C4.5算法繼承了ID3算法的優點,并在以下幾方面對ID3算法進行了改進:
1) 用信息增益率來選擇屬性,克服了用信息增益選擇屬性時偏向選擇取值多的屬性的不足;
2) 在樹構造過程中進行剪枝;
3) 能夠完成對連續屬性的離散化處理;
4) 能夠對不完整數據進行處理。
C4.5算法與其它分類算法如統計方法、神經網絡等比較起來有如下優點:產生的分類規則易于理解,準確率較高。其缺點是:在構造樹的過程中,需要對數據集進行多次的順序掃描和排序,因而導致算法的低效。此外,C4.5只適合于能夠駐留于內存的數據集,當訓練集大得無法在內存容納時程序無法運行。
(3) SLIQ算法
SLIQ算法對C4.5決策樹分類算法的實現方法進行了改進,在決策樹的構造過程中采用了“預排序”和“廣度優先策略”兩種技術。
1) 預排序。對于連續屬性在每個內部結點尋找其最優分裂標準時,都需要對訓練集按照該屬性的取值進行排序,而排序是很浪費時間的操作。為此,SLIQ算法采用了預排序技術。所謂預排序,就是針對每個屬性的取值,把所有的記錄按照從小到大的順序進行排序,以消除在決策樹的每個結點對數據集進行的排序。具體實現時,需要為訓練數據集的每個屬性創建一個屬性列表,為類別屬性創建一個類別列表。
2) 廣度優先策略。在C4.5算法中,樹的構造是按照深度優先策略完成的,需要對每個屬性列表在每個結點處都進行一遍掃描,費時很多,為此,SLIQ采用廣度優先策略構造決策樹,即在決策樹的每一層只需對每個屬性列表掃描一次,就可以為當前決策樹中每個葉子結點找到最優分裂標準。
SLIQ算法由于采用了上述兩種技術,使得該算法能夠處理比C4.5大得多的訓練集,在一定范圍內具有良好的隨記錄個數和屬性個數增長的可伸縮性。
然而它仍然存在如下缺點:
1)由于需要將類別列表存放于內存,而類別列表的元組數與訓練集的元組數是相同的,這就一定程度上限制了可以處理的數據集的大小。
2) 由于采用了預排序技術,而排序算法的復雜度本身并不是與記錄個數成線性關系,因此,使得SLIQ算法不可能達到隨記錄數目增長的線性可伸縮性。
(4) SPRINT算法
為了減少駐留于內存的數據量,SPRINT算法進一步改進了決策樹算法的數據結構,去掉了在SLIQ中需要駐留于內存的類別列表,將它的類別列合并到每個屬性列表中。這樣,在遍歷每個屬性列表尋找當前結點的最優分裂標準時,不必參照其他信息,將對結點的分裂表現在對屬性列表的分裂,即將每個屬性列表分成兩個,分別存放屬于各個結點的記錄。
SPRINT算法的優點是在尋找每個結點的最優分裂標準時變得更簡單。其缺點是對非分裂屬性的屬性列表進行分裂變得很困難。解決的辦法是對分裂屬性進行分裂時用哈希表記錄下每個記錄屬于哪個孩子結點,若內存能夠容納下整個哈希表,其他屬性列表的分裂只需參照該哈希表即可。由于哈希表的大小與訓練集的大小成正比,當訓練集很大時,哈希表可能無法在內存容納,此時分裂只能分批執行,這使得SPRINT算法的可伸縮性仍然不是很好。
貝葉斯分類是統計學分類方法,它是一類利用概率統計知識進行分類的算法。在許多場合,樸素貝葉斯(Na?ve Bayes,NB)分類算法可以與決策樹和神經網絡分類算法相媲美,該算法能運用到大型數據庫中,且方法簡單、分類準確率高、速度快。由于貝葉斯定理假設一個屬性值對給定類的影響獨立于其它屬性的值,而此假設在實際情況中經常是不成立的,因此其分類準確率可能會下降。為此,就出現了許多降低獨立性假設的貝葉斯分類算法,如TAN(tree augmented Bayes network)算法。
? ? ? ?












 工商網監
工商網監
評論